해시테이블
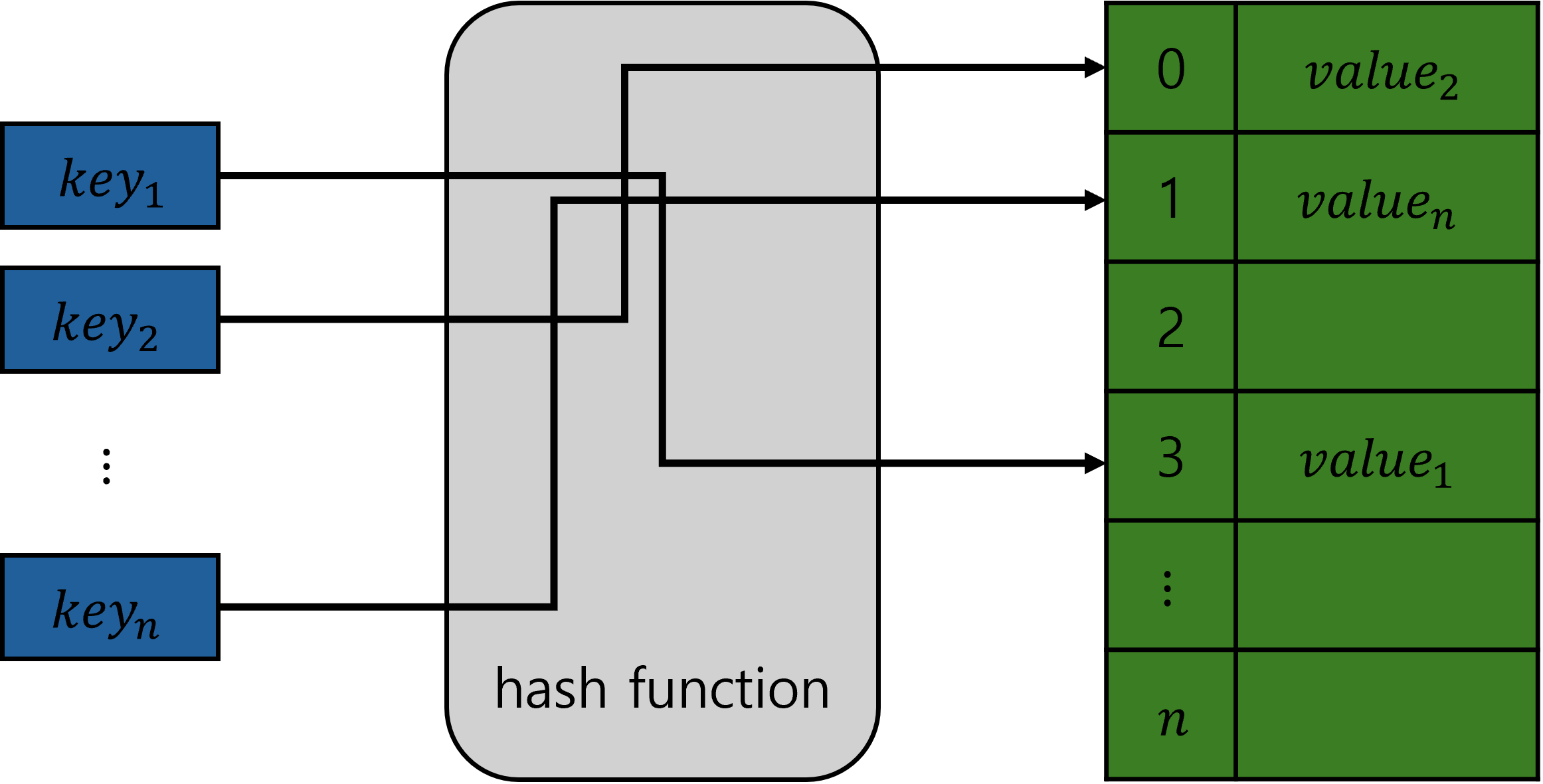
해시테이블이랑 해시를 이용하여 키(key)에 대응되는 값(value)을 저장하는 자료구조이다. 키에 대응되는 값에 빠르게 접근하는 것이 특징인데, 이는 해시 함수(hash function)를 이용하여 키에 대응되는 해시 주소(hash address), 즉 인덱스(index)를 생성하고, 이 인덱스를 통해 배열(버켓, bucket)에 값을 저장하기 때문이다. 배열에 저장하기 때문에 임의접근(ramdom access)이 가능하고, 따라서 잘 만들어진 해시테이블에서 키를 이용하여 값에 접근하는 것의 시간복잡도는 $ \mathcal{O}(1) $ 이다.
해시 함수를 이용하여 키를 테이블 인덱스로 바꾸는 것을 해싱이라 하는데, 이 해싱을 어떻게 할 것이냐가 해시테이블의 접근 성능을 판가름한다. 당연히 해시테이블에서 값이 저장되는 배열은 한정적으로 사용할 수밖에 없기 때문에 해싱 과정에서 키에 대한 인덱스 역시 한정적일 수밖에 없다. 그런데 만약 해싱으로 생성된 인덱스가 그 전에 해싱으로 이미 생성되어 사용중인 인덱스라면 충돌(conllision)이 일어난다. 따라서 이 충돌을 방지하기 위해서도 다양한 방법이 사용된다.
또한 생성한 버켓보다 많은 키와 값을 대응시킬 수 없기 때문에 만약 너무 많은 키와 값을 저장하려 하면 오버플로우(overflow)가 발생한다. 따라서 이를 해결할 수 있는 방법도 반드시 마련되어 있어야 한다.
좋은 해시 함수는 충돌이 적어야 하고, 즉 해시 함수의 값이 고르게 분포되어야 하며, 해시 함수 계산이 빨라 즉각 키를 값에 대응시킬 수있어야 한다.
ADT
해시테이블의 ADT가 아니라 사전구조(dictionary)의 ADT이다.
객체 (Object)
- 일련의 키(key)와 값(value) 쌍의 집합
연산 (Operation)
- add(key, value) ::= key와 value의 쌍을 사전에 추가한다.
- delete(key) ::= key에 해당하는 key와 value의 쌍을 사전에서 삭제한다.
- search(key) ::= key에 해당하는 value를 찾아 있으면 value를 반환하고, 없으면 NULL을 반환한다.
'Data Structure & Algorithm > Data Structure' 카테고리의 다른 글
| [Data Structure] 2-3 트리(2-3 tree) (0) | 2024.12.01 |
|---|---|
| [Data Structure] 균형 이진 탐색 트리(balanced binary search tree)와 AVL 트리 (0) | 2024.12.01 |
| [Data Structure] 보간 탐색(interpolation search) (0) | 2024.11.30 |
| [Data Structure] 순차 탐색(sequential search), 색인 순차 탐색(indexed sequential search) 및 이진 탐색(binary search) (0) | 2024.11.30 |
| [Data Structure] 기수 정렬(radix sort) 및 계수 정렬(counting sort) (0) | 2024.11.27 |