우선순위 큐
우선순위 큐는 일반적인 큐와 달리 우선순위가 높은 데이터가 먼저 나가는 큐이다. 따라서 일반적인 큐처럼 리스트로 구현하면 우선순위가 높은 데이터를 이동시킬 때, 즉 삽입, 삭제를 할 때 시간복잡도가 커지므로 트리를 이용한 힙으로 구현하는 것이 일반적이다.
ADT
객체 (Object)
- 0 개 이상의 우선순위를 가진 요소들의 모임
연산 (Operation)
- create() ::= 우선순위 큐를 생성한다.
- init() ::= 우선순위 큐를 초기화한다.
- is_full() ::= 우선순위 큐가 가득 차 있다면 true 를, 아니라면 false 를 반환한다.
- is_empty() ::= 우선순위 큐가 비어있다면 true 를, 아니라면 false 를 반환한다.
- insert(item) ::= 우선순위 큐에 item을 추가한다.
- delete() ::= 우선순위 큐의 가장 우선순위가 높은 요소를 삭제하고 반환한다.
- find() ::= 우선순위 큐의 가장 우선순위가 높은 요소를 반환한다.
힙
힙은 최대 힙(max heap)과 최소 힙(min heap)으로 나뉜다.

최대 힙은 부모 노드의 키값이 자식 노드의 키값보다 크거나 같은 완전 이진 트리이다. 즉 가장 큰 키값을 가진 노드가 루트 노드가 된다.

최소 힙은 부모 노드의 키값이 자식 노드의 키값보다 작거나 같은 완전 이진 트리이다. 즉 가장 작은 키값을 가진 노드가 루트 노드가 된다.
완전 이진 트리이기 때문에 $ n $ 개의 노드를 가지고 있는 힙의 높이는 $ \lfloor \lg n \rfloor $ 이다. 즉 특정 값 탐색의 시간복잡도는 최악의 상황일 때 $ \mathcal{O}(\log n) $ 이다.
연산
힙에서 삽입은 일단 힙이 완전 이진 트리이기 때문에 완전 이진 트리를 유지하는 자리에 노드를 삽입한다. 그 후 부모 노드와 키값을 비교하면서 힙의 성질을 만족할 때까지 교환한다. 최대 힙인 경우 부모 노드의 키값이 자신보다 클 때까지 부모 노드와 교환하고, 최소 힙인 경우 부모 노드의 키값이 자신보다 작을 때까지 부모 노드와 교환한다.
예를 들어 다음과 같은 최대 힙에 13을 삽입한다고 가정하면 아래와 같은 연산이 이루어진다.

13의 키값을 가진 노드를 완전 이진 트리를 유지하는 가장 마지막 노드에 삽입한다.

부모 노드의 키값과 비교하고, 부모 노드의 키값이 더 작으므로 교환한다.

다시 부모 노드의 키값과 비교하고, 부모 노드의 키값이 더 작으므로 교환한다. 다시 한번 부모 노드와 비교하면 부모 노드의 키값이 더 크므로 교환을 종료한다. 즉 삽입이 끝난다.
힙에서 삭제 역시 비슷하게 이루어진다. 먼저 우선순위 큐의 특징에 따라 키값이 가장 큰(혹은 가장 작은) 루트 노드를 삭제한다. 그 후 완전 이진 트리에서의 마지막 노드를 루트 노드에 올린다. 그 후 자식 노드와 비교해가며 알맞은 자리를 찾으면 된다.
예를 들어 아래와 같은 최대 힙에서 삭제가 일어난다 해보자.

삭제할 루트 노드를 삭제한다.

완전 이진 트리의 마지막 노드를 루트 노드로 대체한다.

자식 노드와 비교하고 자식 노드가 더 크다면 교환한다.

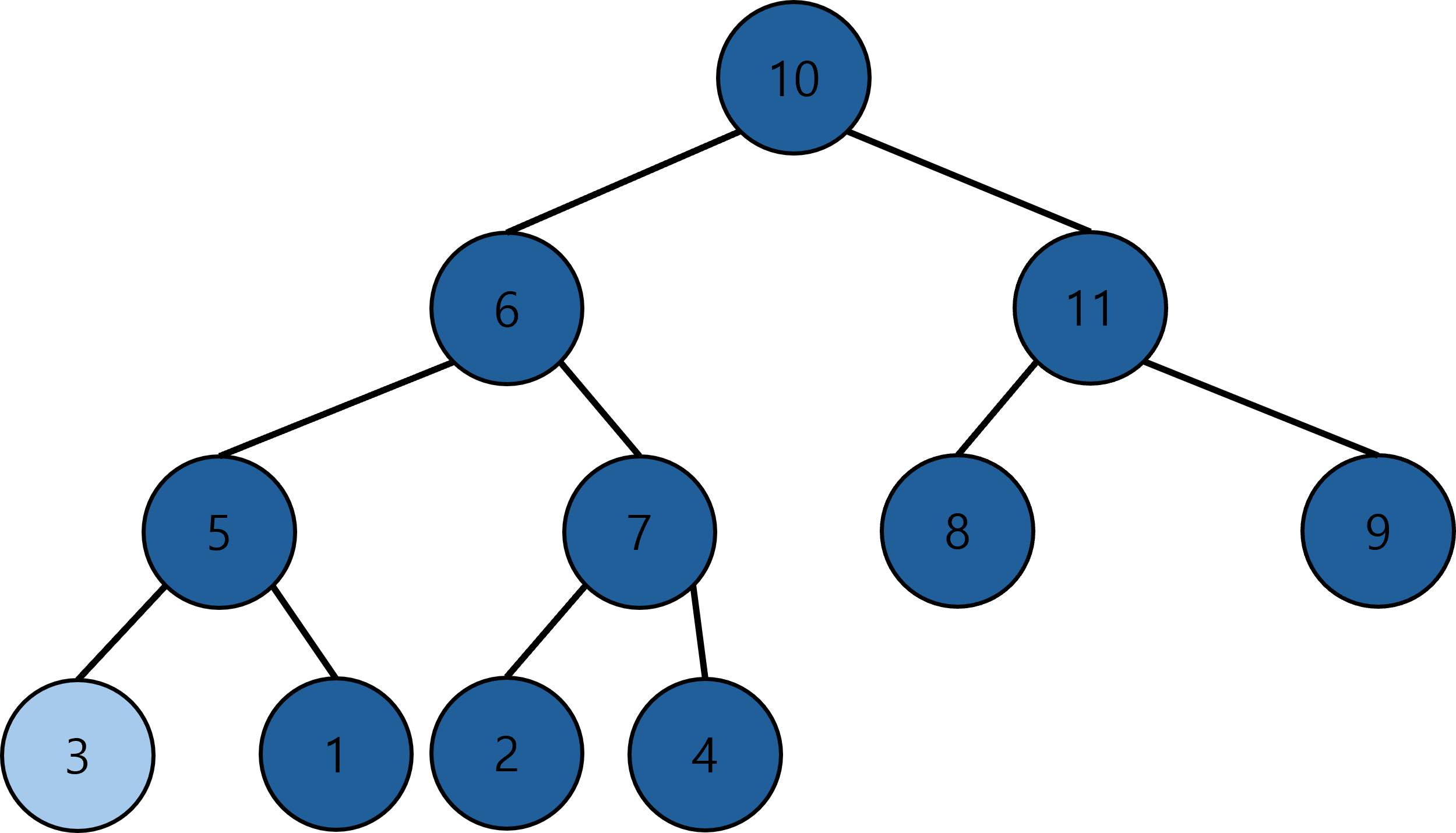
교환이 더 이상 이루어지지 않는다면 삭제가 끝난 것이다.
삽입과 삭제 연산 모두 최악의 경우 힙의 높이만큼 올라가거나 내려가야 하기 때문에 시간복잡도는 $ \mathcal{O}(\log n) $ 이다.
구현 | C
완전 이진 트리이므로 각 노드에 레벨 순으로 번호 붙이고, 이 번호를 배열의 인덱스로 하여 구현할 수 있다. 이중 연결 리스트로도 구현 가능하지만, 배열에 비해 이점이 크지 않으므로 배열로 구현하는 것이 일반적이다.
왼쪽 자식의 인덱스는 부모의 인덱스의 두 배이고, 오른쪽 자식의 인덱스는 왼쪽 자식 인덱스에 하나를 더하면 된다. 반대로 부모의 인덱스는 자식 인덱스의 반의 버림이다.
다음은 C 를 통해 구현한 힙이다. 배열로 구현하였고, element 는 임의로 int 로 설정하였다.
#include <stdio.h>
#include <stdlib.h>
#define HEAP_SIZE 100
typedef struct {
int key;
} element;
typedef struct {
element heap[HEAP_SIZE];
int heap_size;
} Heap;
Heap* create() {
return (Heap*)malloc(sizeof(Heap));
}
void init(Heap* h) {
h->heap_size = 0;
}
void insert_max_heap(Heap* h, element item) {
int i = ++(h->heap_size);
while ((i != 1) && (item.key > h->heap[i/2].key)) {
h->heap[i] = h->heap[i/2];
i /= 2;
}
h->heap[i] = item;
}
element delete_max_heap(Heap* h) {
int parent, child;
element item, temp;
item = h->heap[1];
temp = h->heap[(h->heap_size)--];
parent = 1;
child = 2;
while (child <= h->heap_size) {
if ((child < h->heap_size) && (h->heap[child].key) < h->heap[child+1].key) {
child++;
}
if (temp.key >= h->heap[child].key) {
break;
}
h->heap[parent] = h->heap[child];
parent = child;
child *= 2;
}
h->heap[parent] = temp;
return item;
}간단히 아래와 같이 main 함수를 만들어 실행해보겠다.
int main(void) {
element e1 = {5}, e2 = {4}, e3 = {12};
element e4, e5, e6;
Heap* heap = create();
init(heap);
insert_max_heap(heap, e1);
insert_max_heap(heap, e2);
insert_max_heap(heap, e3);
e4 = delete_max_heap(heap);
printf("<%d> ", e4.key);
e5 = delete_max_heap(heap);
printf("<%d> ", e5.key);
e6 = delete_max_heap(heap);
printf("<%d> \n", e6.key);
free(heap);
return 0;
}출력은 다음과 같다.
<12> <5> <4>비오름차순으로 정렬되어 출력되는 것을 확인할 수 있다.
백준의 최대 힙(링크)을 활용하여 힙을 구현하고 연습해볼 수 있다.
'Data Structure & Algorithm > Data Structure' 카테고리의 다른 글
| [Data Structure] 그래프 깊이 우선 탐색(DFS, depth first search) 및 너비 우선 탐색(BFS, breath first search) (0) | 2024.11.18 |
|---|---|
| [Data Structure] 그래프(graph) (0) | 2024.11.18 |
| [Data Structure] 이진 탐색 트리(binary search tree) (0) | 2024.11.14 |
| [Data Structure] 스레드 이진 트리(threaded binary tree) (0) | 2024.11.14 |
| [Data Structure] 이진 트리 순회(binary tree traversal) 및 활용 (0) | 2024.11.14 |