기수 정렬

여러 정렬들이 각 값을 비교한 후 알맞은 위치를 찾아가는 것과 다르게 어떤 정렬들은 값을 비교하지 않고 정렬한다. 기수 정렬이 대표적인 예시이다.
사용하는 진법에 맞게 버킷을 만들고, 버킷에 차례대로 넣고, 작은 순서대로 꺼내면 정렬이 된다. 한자리 수들로 이루어진 리스트를 정렬하는 경우 버킷에 넣다 빼는 것을 한번만 하면 되지만, 두자리 수가 있다면 두번, 세자리 수가 있다면 세번 넣었다 빼야한다. 즉 리스트의 길이에 큰 영향을 받는 다른 정렬 방식과 다르게 리스트 내 최대값의 자리수에 영향을 더 많이 받는다는 특징이 있다.
예시

예를 들어 위와 같은 리스트를 정렬한다고 해보자. 먼저 아래와 같이 버킷을 만들어주어야 한다.

가장 낮은 1의 자리를 기준으로 버킷에 차례로 담아준다.


$$ \vdots $$
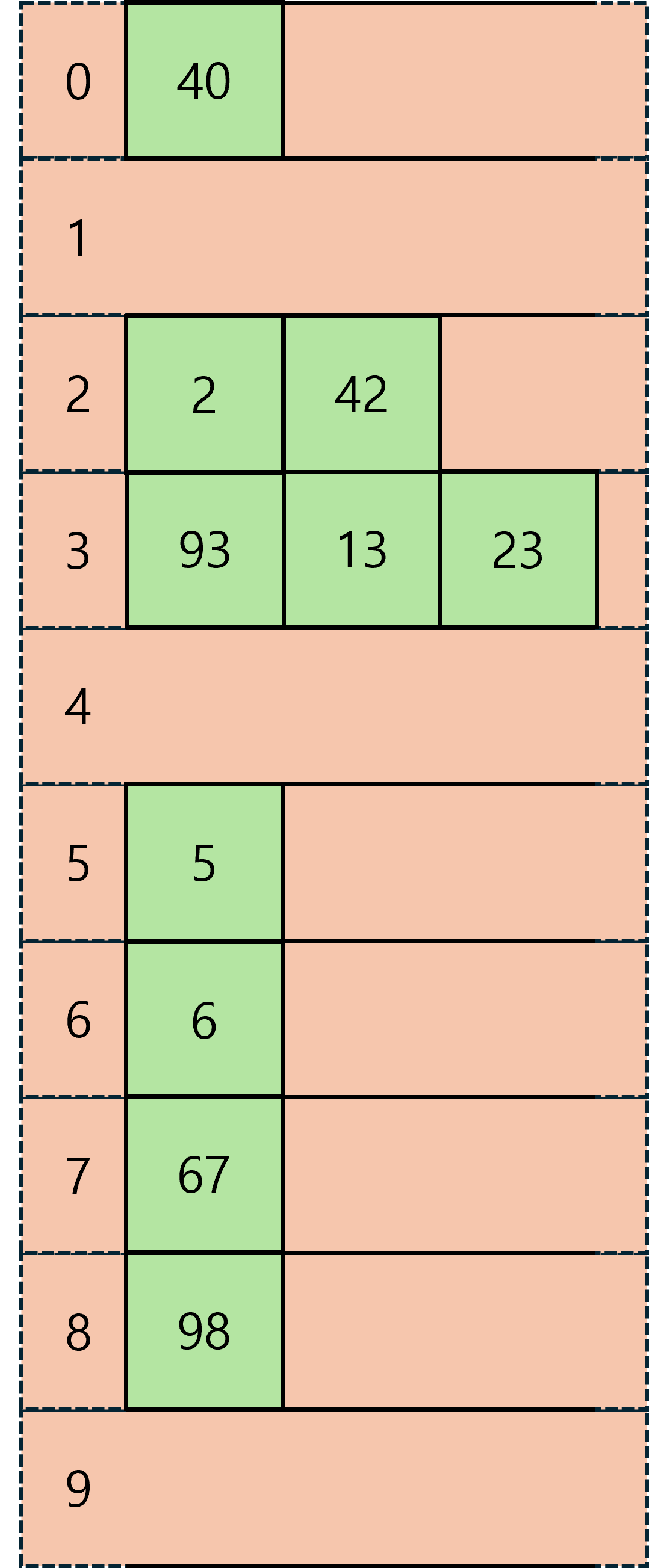
모두 담았다면 위에서 부터 차례대로 빼서 다시 리스트에 담아준다.


$$ \vdots $$

모두 꺼내면 1의 자리를 기준으로 정렬이 끝난다.

이제 다시 버킷에 담아준다. 단 1의 자리가 아니라 10의 자리를 기준으로 담아준다. 그 후 차례로 꺼내준다.


$$ \vdots $$

$$ \vdots $$

정렬이 완료되었다.

가장 큰 값의 자릿수가 두자리여서 버킷에 두번 담았다가 빼는 것으로 정렬이 끝났다. 다른 정렬과 다르게 비교를 사용하지 않고, 차례로 버킷에 넣고 빼주는 것으로 정렬이 되었다는 특징이 있다.
리스트의 최대값의 자리수에 따라 연산 횟수가 바뀌고, 최대값의 자리수를 $ k $ 라 할 때 기수 정렬의 시간복잡도는 언제나 $ \mathcal{O}(kn) $ 이다. 리스트 내의 값이 큰 차이가 없는 상황에서는 대부분의 정렬보다 빠르게 동작하겠지만, 리스트의 크기는 작은데 최대값은 매우 큰 경우라면 굉장히 비효율적인 정렬이 될 것이다.
또한 큰 단점이 비교 연산이 없으므로 비교를 통해서만 정렬할 수 있는 것들, 예를 들어 한글, 실수 등에 대해서는 정렬이 불가능하다는 단점이 있다. 비교 연산이 없다는 것이 장점이면서 단점인 것이다.
구현 | C
사용하는 진법과 최대 자리수를 따로 설정하였다. 최대 자리수는 리스트를 입력받은 후 계산하여 설정할 수도 있겠고, 양수만 가정하였기에 진법에 맞춘 버킷을 사용하지만, 음수도 정렬하려면 진법의 두배를 사용해야 할 것이다.
#define BUCKETS 10 // 사용하는 진법
#define DIGITS 4 // 최대 자리수
void radix_sort(int list[], int n) {
int factor = 1;
Queue queue[BUCKETS];
for (int b = 0; b < BUCKETS; b++) {
init(&queue[b]);
}
for (int d = 0; d < DIGITS; d++) {
for (int i = 0; i < n; i++) {
enqueue(&queue[(list[i]/factor)%10], list[i]);
}
for (int b = 0, i = 0; b < BUCKETS; b++) {
while (!is_empty(&queue[b])) {
list[i++] = dequeue(&queue[b]);
}
}
factor *= 10;
}
}
계수 정렬
계수 정렬은 쉽게 말하면 기수 정렬에서 버킷을 굉장히 많이 만들어서 한번 버킷에 넣었다 빼는 것으로 정렬을 끝내는 것이다. 버킷의 수를 리스트의 최댓값으로 두고, 각 버킷에 맞는 수를 채워넣고 추출하면 정렬이 끝난다. 즉 기수 정렬이 $ \mathcal{O} (kn) $ 의 시간복잡도를 가지고 있을 때 $ k $ 를 $ 1 $ 로 만들어주는 것이다.
장점이 기수 정렬의 장점을 극대화시킨 것이라면 단점도 기수 정렬의 단점을 극대화시킨 것인데, 바로 최댓값이 클 때 버킷을 미친듯이 만들어야 한다는 것이다. 극단적 예로 $ [ 1, 2, 9, 10^9 ] $ 라는 리스트를 정렬한다고 해보자. 보통의 정렬이라면, 아니 심지어 가장 비효율적인 버블 정렬이라 해도 $ \mathcal{O}(n^2) $ 의 시간복잡도를 가지므로 $16$ 번 정도의 연산이면 정렬이 완료된다. 그런데 이걸 계수 정렬을 이용해 정렬하려 한다면 일단 버킷을 $ 10^9 $ 개 만들어야 한다. 그 후 각 수를 알맞은 버킷에 넣고, $0$번 버킷부터 차례대로 수를 꺼내와서 정렬해야 한다. 일단 버킷을 만드는 것은 둘째치고, 버킷에서 넣고 꺼내오는 연산만 $ 2 \times 10^9 $ 번 해야하기 때문에 압도적으로 비효율적이다. 그러나 만약 중복된 값이 많고 최댓값이 작은 리스트를 정렬해야 한다면, 메모리 공간이 여유롭다면 계수 정렬은 최고의 정렬이 될 수 있다.
시간복잡도는 최댓값을 $ k $ 라 할 때 $ \mathcal{O} (n+k) $ 이다.
구현 | C
최댓값을 구하는 함수 max 는 따로 구현하면 된다.
void counting_sort(int list[], int n) {
int* count = (int*)calloc(max(list)+1,sizeof(int));
for (int i = 0; i < n; i++) {
count[list[i]]++;
}
for (int i = 0, j = 0; i <= max(list); i++) {
if (count[i] != 0) {
for (int k = 0; k < count[i]; k++) {
list[j++] = i;
}
}
}
}
'Computer Science and Engineering > Data Structure' 카테고리의 다른 글
| [Data Structure] 보간 탐색(interpolation search) (0) | 2024.11.30 |
|---|---|
| [Data Structure] 순차 탐색(sequential search), 색인 순차 탐색(indexed sequential search) 및 이진 탐색(binary search) (0) | 2024.11.30 |
| [Data Structure] 병합 정렬(merge sort) (0) | 2024.11.27 |
| [Data Structure] 힙 정렬(heap sort) (0) | 2024.11.26 |
| [Data Structure] 퀵 정렬(quick sort) (0) | 2024.11.26 |