
데이터 시각화
데이터를 확인할 때 데이터 그 자체로 보면 데이터의 특징을 파악하기 어렵다. 따라서 다양한 방법으로 데이터를 요약하거나 시각화하여 데이터의 특징을 파악하기도 한다.
데이터를 파이썬으로 시각화할 때는 seaborn, matplotlib 등의 라이브러리를 사용하는데, 판다스에서도 간단하게는 시각화할 수 있기 때문에 간단하게 데이터의 특징을 파악할 때는 판다스의 메소드를 활용하는 편이 좋을 수 있다.
데이터를 시각화할 때는 수치형 데이터와 범주형 데이터를 다르게 시각화하는 것이 일반적이다. 또한 시각화 메소드 또한 수치형 데이터냐, 범주형 데이터냐에 따라 다르게 동작하기 때문에 수치형 데이터를 시각화하는 메소드를 범주형 데이터에 사용하면 당연히 오류가 나기 때문에 미리 데이터의 정보를 파악(참고 링크)하고 시각화해야 한다.
아래에서 보여줄 데이터는 seaborn의 iris 데이터셋을 사용하겠다.
import seaborn as sns
import pandas as pd
df = sns.load_dataset('iris')
수치형 데이터 시각화
기본적으로 수치형 데이터는 히스토그램(histogram), 산점도(scatter plot), 선 그래프(line plot), 박스 플롯(box plot) 등으로 시각화한다. 각 방식마다 장단점이 있으므로 용도에 맞게 선택하면 된다. (자료 시각화 참고)
df_num = df.select_dtypes(include="number")위 코드를 통해 범주형 데이터인 species를 제거하고 iris 데이터셋을 사용하겠다.
• 히스토그램
plot.hist(참고링크)를 이용하면 된다.
df_num.plot.hist()
가장 간단하게는 위와 같이 시각화할 수 있다.
매개변수인 bins를 통해 구간을 설정할 수 있다. 예를 들어 구간을 30으로 설정하면 다음과 같다.
df_num.plot.hist(bins=30)
• 산점도
plot.scatter(참고링크)를 이용하면 된다.
df_num.plot.scatter(x="petal_length", y="petal_width")
간단하게 위와 같이 시각화할 수 있는데, 무조건 x와 y를 설정해주어야 한다.
추가로 매개변수 c를 통해 색상을, s를 통해 점의 크기를 설정해줄 수 있다.
• 선 그래프
plot.line(참고링크)를 이용하면 된다.
df_num.plot.line()
기본적으로는 x축에 인덱스가 들어가고 y축에 해당 값이 들어가는데, 매개변수를 통해 x와 y를 설정할 수도 있다. 주로 시계열 데이터에 많이 사용된다.
• 다양한 매개변수
plot(참고링크)을 통해 시각화할 때 다양한 매개변수(parameter)를 활용할 수 있다. 위에서 사용된 plot.hist, plot.scatter, plot.line 와 그 외 플롯들을 사용하려면 plot 메소드의 매개변수 kind에 "hist", "scatter", "line" 등을 넣어주면 된다.
df_num.plot(kind="line") # df_num.plot.line()과 같음title, xlabel, ylabel 을 통해 전체 이름, x축 이름, y축 이름을 넣을 수 있고, fontsize를 통해 글꼴 크기를 조정할 수 있다.
df.plot(kind="scatter", x="petal_length", y="petal_width", xlabel="Petal length", ylabel="Petal width", title="Petal size", fontsize=7)예를 들어 위와 같은 코드의 출력은 아래와 같다.
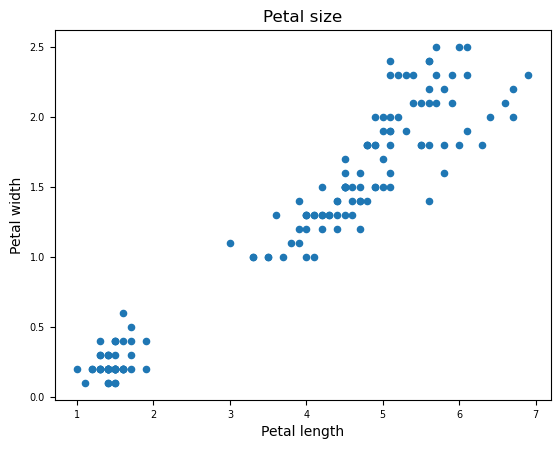
그 외에도 다양한 매개변수를 활용할 수 있고, 각 플롯에 맞는 매개변수가 필요한 경우 선택하여 사용하면 된다.
• 박스 플롯
boxplot(참고링크)를 이용하면 된다.
df_num.boxplot()
박스 플롯을 보는 법은 여기(링크)를 참고하면 되고, 매개변수는 위 boxplot 링크를 참고하면 된다.
범주형 데이터 시각화
기본적으로 범주형 데이터는 각 범주의 빈도가 중요하기에 막대 그래프(bar plot)를 주로 사용하여 시각화한다. 원 그래프(pie chart)를 사용하는 경우도 있지만, 범주가 조금이라도 많아지면 원 그래프는 알아보기 힘들어서 잘 사용하지 않는다.
• 막대 그래프
plot.bar(참고링크) 혹은 plot.barh(참고링크)를 이용하면 된다. bar는 세로이고, barh는 가로이다.
이때 주의해야 할 것은 각 빈도를 보기 위해서 범주형 데이터를 선택하고, value_counts를 통해 빈도를 계산한 후에 시각화해주어야 한다.
df["species"].value_counts().plot.bar()
앞서 value_counts를 이용해서 빈도를 구한 후에 plot.bar 메소드를 사용했기 때문에 x축에 범주가 들어가고 y축에 카운팅된 값이 들어가는데, 따로 value_counts를 사용하지 않고, x와 y 매개변수를 통해 설정할 수도 있다. 그러나 대부분 경우 범주의 빈도를 구하는 경우가 많기 때문에 value_counts를 사용하여 시각화하는 편이 편리하다.
color 매개변수를 통해 색을 설정할 수도 있다. 이때는 리스트로 각 범주에 해당하는 값을 지정하여 줄 수 있다.
df["species"].value_counts().plot.barh(color=["#30323D", "#5C80BC", "#CDD1C4"])
'Data Science > Data Processing' 카테고리의 다른 글
| [Pandas] 데이터프레임 연결(concatenate) 및 결합(merge), 그리고 간단 결합(join) (0) | 2024.12.30 |
|---|---|
| [Pandas] 값 혹은 인덱스를 기준으로 데이터프레임 정렬 (0) | 2024.12.29 |
| [Pandas] 데이터프레임 기초 통계량 확인 (0) | 2024.12.26 |
| [Pandas] 데이터 정보 확인과 미리보기 및 결측치 확인과 처리 (0) | 2024.12.25 |
| [Pandas] 판다스 csv, 엑셀(xlsx, xls) 불러오기 및 저장하기 (0) | 2024.12.25 |